ORB Basics
- What does an ORB do?
- What are the parts of an ORB?
- How does the dynamic invocation interface (DII) work?
- What about the stubs?
- What's in the ORB interface?
- What happens on the Object Implementation side?
- How does CORBA support load-balancing?
- How does CORBA support Fault Tolerance?
- What's a Servant in CORBA?
- Tell me more about the POA, then.
- What are the POA policies?
- What are the Service, Session, Process, and Entity patterns?
What does an ORB do?
That's a big question, and it would take more than one page to explain it all. But, we'll cover the basics on this page and, when you've finished reading it, you'll be in a good position to learn more if you want to. If you're using an ORB now, you can learn by reading the documentation that came with it. Another place to look is the OMG CORBA specification, in particular Chapters 2, 4, and 11.
In CORBA, the Object Request Broker or ORB takes care of all of the details involved in routing a request from client to object, and routing the response to its destination.
There's more that just that, of course. The ORB is also the custodian of the Interface Repository (abbreviated variously IR or IFR), an OMG-standardized distributed database containing IDL interface definitions. (The IFR is defined in Chapter 10 of the OMG CORBA specification.)
On the client side, then, the ORB offers a number of services: It provides interface definitions from the IFR, and constructs invocations for use with the Dynamic Invocation Interface (DII). It also converts Object References between session and stringified format, and (for CORBA 2.4 and later ORBs) converts URL-format corbaloc and corbaname object references to session references.
On the server side, the ORB has even more to do. Although CORBA allows (in fact, requires) the client to assume that every valid object reference corresponds to a running instance, it is likely that the code of the instance is not running. That's because, in order to conserve server resources, the ORB de-activates inactive objects, and re-activates them whenever a request comes in. CORBA supports a number of activation patterns, so that different object or component types can activate and de-activate in the way that uses resources best.
What are the parts of an ORB?
Here's a diagram of an ORB, from OMG's Object Management Architecture Guide:
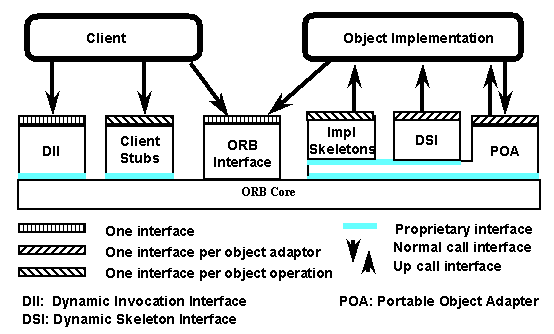
We'll describe each part of the ORB, briefly(!), working our way across from left to right. The diagram covers only the ORB pieces that interact with the client and the object implementation, leaving out pieces that interact with the operating system and the network. Since this tutorial is for ORB users (that is, application programmers or application users) and not for ORB builders, we're going to leave out discussion of these more technical aspects also.
How does the dynamic invocation interface (DII) work?
DII-based invocations differ from stub-based invocations in the same way that scripts differ from programs: they're interpreted at run time, and not compiled in a previous step. Using the DII, a client can invoke an operation on a new type of object that it's just discovered (for example, using the Trader Service). It's not trivial, of course - the client programmer must write code to retrieve the object's IDL interface definition from the IFR, and construct an invocation using interfaces defined on the ORB. The invocation itself is a CORBA object with its own object reference.
Because the interface-dependent marshalling is done by the ORB and not by interface-specific compiled code, there is only one DII, serving every instance of every object type.
Until the recent adoption of the CORBA Messaging Service, the DII was also the only way to execute a non-synchronous query and receive a reply from it.
We're not going to describe how to use the DII in this tutorial. To learn about it, download and read Chapter 7 of the OMG CORBA specification.
What about the stubs?
We've already discussed how the stubs are produced by the IDL compiler, each one marshaling the arguments called for in its definition. There is a separate stub for each operation of each interface. Since a typical client invokes operations on only a handful of object types, there are only a limited number of stubs linked into a typical executable. (A client may invoke operations on hundreds or more of instances of these types, but this involves only changing object references, and does not increase the number of stubs.) However, if you're writing a client for a small device and it invokes on more than a few object types, you may be impacted by the memory footprint of the stubs in your executable.
Because we've covered most of the stub basics already, and we don't have room to cover details here, that's about it for stubs. They're important, even though we only gave them a paragraph on this page. (They got a lot more on the basic page, and in our IDL discussion!)
What's in the ORB interface?
The ORB interface provides access to every ORB service except client invocations (which go through the stubs or the DII), and object activations and calls (which come through the object adapter, typically a POA).
These services include:
- Access to initial services such as the Naming Service, Trader Service, Root POA, and others, via list_initial_services and resolve_initial_refererences.
- Access to the IFR, and construction of DII invocations.
- Object reference operations, including conversion of Object References between session and stringified format,. This also includes (for CORBA 2.4 and later ORBs) conversion of URL-format corbaloc and corbaname object references to invokable references. Also creation of duplicate object references, and releasing storage for object references.
- Policy operations including create_policy.
- valuetype factory operations.
- Thread-related operations including work_pending and perform_work.
If you're interested in learning more about any of these services, you can download the OMG CORBA specification and read more. In this beginners' tutorial, we can only introduce these advanced topics for your awareness.
What happens on the Object Implementation side?
A lot, especially if you're running the kind of large-scale internet or enterprise server that makes most effective use of CORBA, with many (hundreds of thousands? millions? more?) clients or object instances.
CORBA deliberately keeps the client-side architecture simple, for many good reasons. Because of this, all of the mechanisms for scalability reside on the server (object implementation) side. CORBA's design supports scalability with many features. We'll introduce some of them here.
We haven't said exactly where the ORB is, and for good reason. CORBA defines the ORB solely in terms of the services it provides and the interfaces you invoke to obtain those services. An ORB implementor is free to locate the code that implements those services anywhere he likes. So, some ORBs run all of their functionality in a single process on the same machine as their clients and servers, as you probably imagined before we started this discussion. On the other hand, some ORBs spread their work over multiple processes on a single machine, and others spread their work over many machines using the network. If you're writing an ORB for a small device, this is a good way to provide full functionality in a reasonable footprint. And, many vendors market robust enterprise ORBs that run, load-balanced and fault-tolerant, spread over a roomful of capable server machines multiply connected by fast network links. In this case, you can consider the entire roomful of machines to be a single ORB!
How does CORBA support load-balancing?
Until now, there has been no load-balancing service in CORBA. There is enough native support in GIOP, OMG's standard protocol, to support the re-direction necessary for load balancing in a robust and standard way. The LOCATION_FORWARD exception status, and the LocateReply message, are the specific features that load-balanced ORBs use. They enable an ORB vendor to establish one or several machines as "dispatchers" that receive a client's initial request, designate a lightly-loaded machine as a proper host for the requested instance, and re-direct the client's invocations to it. This load-balancing mechanism is standard, and works even on cross-vendor invocations.
CORBA does not, however, standardize interfaces that allow an object or server implementation to work with the ORB on load balancing. An RFP expected to be issued by the OMG in late April, 2001, will standardize these interfaces. We'll post a link to it as soon as it's issued.
How does CORBA support Fault Tolerance?
A relatively new specification, already available on the market in at least one commercial product, supports Fault Tolerance with a standardized infrastructure based on entity redundancy at the object level. You can download and read the specification here.
What's a Servant in CORBA?
We need to define and explain six related terms here:
- From the client's point of view, a CORBA object is an entity with an object reference that provides the operations defined in its interface. These operations are always available to the client, from the time the object instance is created until the time it is destroyed.
- Object creation and destruction delimit an object's lifetime. Creation of the object reference denotes creation of the object itself. (In fact, because executing CPU and memory resource may be assigned to the object "on the fly", separately for each invocation, the phrase "creation of the object itself" has no meaning beyond creation of the object reference.) Object destruction is irrevocable - once destroyed, an object can never be invoked again. Its object reference does not work, and will never work again. There is no such thing as a defibrillator that can bring destroyed CORBA objects back to life!
- Object activation and deactivation are visible to the server only. Clients are never aware that an object has been activated or deactivated - to the client, every object that exists (i.e. has been created and has not been destroyed) is running, at least in the sense that it is available for invocation. Activation denotes that a CORBA server has allocated and configured CPU and memory resource to perform the operations of the object instance; deactivation denotes that these resources have been reclaimed. If the object has state, that state must be saved to persistent storage on deactivation and restored from storage on subsequent activation. Because this happens, the client is unaware that a deactivation/activation cycle has occurred. CORBA servers may select from several hundred different patterns of servant activation/deactivation, through POA policies. CORBA Component servers may choose from four pre-selected patterns.
- The servant, visible only to the server, is the executing CPU and memory resource that performs an object's operation. It is activated and deactivated according to the pattern selected by POA policies. The association between a servant and an object is a run-time concept, and may be set as frequently as as per-invocation. For different object types or instances, there may be one servant for one object, or many servants (over time) for a particular object, or one servant serving many objects. This flexibility allows a set of server hardware and software to serve many more objects than would be possible in a system that required a single representation for the running code for every object. The object-oriented principle of encapsulation hides the servant implementation, including activation and deactivation operations, from the client. The client only knows that it invoked an operation defined on the object's IDL interface, and the response came back.
All of these server-side operations are performed by the Portable Object Adapter (POA).
Tell me more about the POA, then.
The Portable Object Adapter (POA) is the piece of the ORB that manages server-side resources for scalability. By deactivating objects' servants when they have no work to do, and activating them again when they're needed, we can stretch the same amount of hardware to service many more clients.
Although it is architecturally a separate piece of the ORB, and ORBs can conceivably have more than one type of object adapter, the POA is not a piece of software that you can buy separately from the ORB. In fact, the interfaces that connect the ORB and the POA are proprietary, and there is no reason for a vendor to disclose them. The POA is, in fact, the second object adapter that OMG has specified. First was the Basic Object Adapter or BOA, now deprecated. Designed in 1990, the BOA was a major step forward at the time, but much too primitive to meet enterprise and Internet requirements now that network usage has become much more demanding.
The programmer fixes resource allocation/de-allocation patterns by setting POA Policys. These determine whether object references created by the POA are transient or persistent; whether activation is per-method-call or longer or shorter; and how multiple CORBA objects (either of a single type, or multiple types) map to servants. There are seven POA policies; when you multiply out the different settings, you come up with nearly 200 possible combinations. Of these, the CORBA Component Model (CCM), which we won't describe further here (but you can read about it here or here), has picked the four most useful and institutionalized them as pre-coded alternatives. Their names, reminiscent of Enterprise JavaBeans types (intentionally!), are Service, Session, Process, and Entity. You can code to these useful patterns using a bare POA without the CCM too, so we'll describe them here.
What are the POA policies?
Of the seven POA policies, we need to cover three in order to explain the four basic resource allocation patterns that we just named. So we'll do this, and send you to the specifications, your ORB product's documentation, or a good book for the rest of the details.
LifespanPolicy of the object or component reference may be either TRANSIENT or PERSISTENT. TRANSIENT object references become invalid when a server goes down, even if the object they refer to has not been deleted. It's bad programming practice to put a TRANSIENT object reference into a persistent store such as a Naming or Trader service, so don't ever do it. The big difference between these two policies lies "under the covers" and really comes to the fore when you execute load-balanced on a multi-machine server ORB: PERSISTENT object references use all of the ORB's capabilities to execute reliably, with loads balanced on a per-object, per-session basis. On the other hand, TRANSIENT object references access none of this machinery - their servants may be placed on a lightly loaded machine initially, but they never migrate since the ORB expects that their lifetime will be shorter than the time constant of its shifting load pattern.
ServantRetentionPolicy may be RETAIN or NON-RETAIN. Under NON-RETAIN, a servant is de-activated as soon as it returns from an invocation. Under RETAIN, a servant remains activated and its assignment to a CORBA object reference is recorded in the POA's Active Object Map so that future invocations can be routed directly to it. This saves time when multiple invocations come in quick succession, but consumes resource even when the servant isn't doing anything useful (which is typically most - almost all - of the time).
IdAssignmentPolicy may be SYSTEM_ID or USER_ID. This affects allocation of the ObjectID, a string which ORB and servant use to locate storage to restore state on re-activation after either de-activation or a system crash. Under SYSTEM_ID, the ORB assigns the ID; under USER_ID the programmer (not the end-user!) chooses the string. When the ORB re-activates a servant, it passes the ObjectID to it before the invocation. The servant uses the ObjectId to restore its state, and tells the POA. Only then does the POA pass the invocation to the servant for execution.
What are the Service, Session, Process, and Entity patterns?
The CORBA Component Model defines four particularly useful resource utilization patterns. You can make use of these patterns in POA programming, without using Components, so we'll use those four patterns and their names here. The patterns are Service, Session, Process, and Entity. (Yes, two of these names are the same as EJB's, quite intentionally.)
Of the four patterns, the Service pattern uses your server resources the most efficiently. A Service object or component - including its object reference - is used once, and then destroyed and its resources reclaimed. Service objects have Transient object references, saving server resources. Your application will run most efficiently if you take as much "use once" functionality out of long-running objects and put it into service objects. For example, take the "purchase contents" function out of your shopping cart (where it would stay resident as long as the shopping cart is used for any shopping purpose) and put it into a "purchase" Service object, called by the shopping cart only once, when your customer pushes the "purchase" menu button.
The Session pattern also uses a temporary object reference, but lasts for several calls by the same client. Because its reference is temporary, you would not register it in persistent storage such as a Naming or Trading service. Use Session objects for iterators or other objects that will be called some limited number of times in quick succession by the same client, and then discarded. Try to avoid using persistent storage for a Session object; if your server crashes and then comes up again, the object and its storage will no longer be accessible. (If you're using this pattern for an iterator holding multiple megabytes of data, this may be unavoidable.)
The Process pattern is the first one we'll discuss with a persistent object reference, allowing you to store it in a Naming or Trading service and access persistent storage (but see the next category before you do this!) without violating good programming practice. Use this pattern to represent a medium-term process' functionality. Examples of good use include applying for a mortgage (but not the mortgage itself), or a shopping cart that may be used across web sessions. (If you only allow a cart to last for a single web session, use the Session pattern instead.)
The Entity pattern also has a persistent object reference, and has a strong identity. Use this pattern to represent data in your database to your application. Your application will be most efficient if you code these objects to be a thin layer between your datastore and your application - they represent your data, and do nothing else. In the CORBA Component Model, Entity components have strong identity, with their references stored by the container in a flat Naming service.
Top